
当前AI模型正向超大规模发展,对数据、算力等资源的需求急速增长,普通的单算力集群已难以满足需要。随着国家“东数西算”工程逐步展开,全国各地构建起不同功能的算力中心,为AI模型发展提供强大支撑的同时,也使异地计算成为今后模型训练通常面临的场景。因此,如何在大模型训练任务中调度使用跨地域集群算力、利用不同集群上的数据、复用不同集群上的已有模型,则是有待解决的关键问题。
对此,鹏城实验室与百度联合研发了面向云际协同训练场景的深度学习统一训练框架“鹏城-百度·星云(Nebula-I)”(以下简称“星云”框架),在算力共享、模型共享和大模型服务层面进行了探索和实验,并实现了最大化通信性能的同时使模型精度损失最小化的目的。“星云”框架已于5月20日举行的百度WAVE SUMMIT 2022深度学习开发者峰会上正式发布,相关技术报告已发表在预出版网站Arxiv(见https://arxiv.org/abs/2205.09470)。

相洋副所长作峰会主题报告
峰会上,鹏城实验室网络智能部开源研究所副所长相洋在题为“超大规模模型训练超算化的趋势及应用”的主题报告中,分析了当前大模型训练存在的痛点和解决方案,分享了鹏城实验室在AI大模型研制和智算网络建设方面的一系列成果,介绍了“星云”框架在低带宽异构多云场景下、在AI大模型预训练和微调任务上的可行性。
相洋介绍,目前鹏城实验室正探索构建以“鹏城云脑”大科学装置为枢纽、汇集国内多家算力中心资源的人工智能算力网络,并初步搭建了面向多中心的云际协同训练环境。基于此,鹏城实验室与百度联手研发了“星云”框架,其由任务层、训练优化层、并行计算层、通信优化层、安全和隐私层、管理和调度层和云硬件层等七个层级构成。其中,训练优化层、并行计算层和通信优化层共同组成了Nebula-Optimizer,“从训练策略、并行策略和通信策略三个方面对训练过程进行联合优化,实现了最大化通信性能的同时使模型精度损失最小化的目的。”
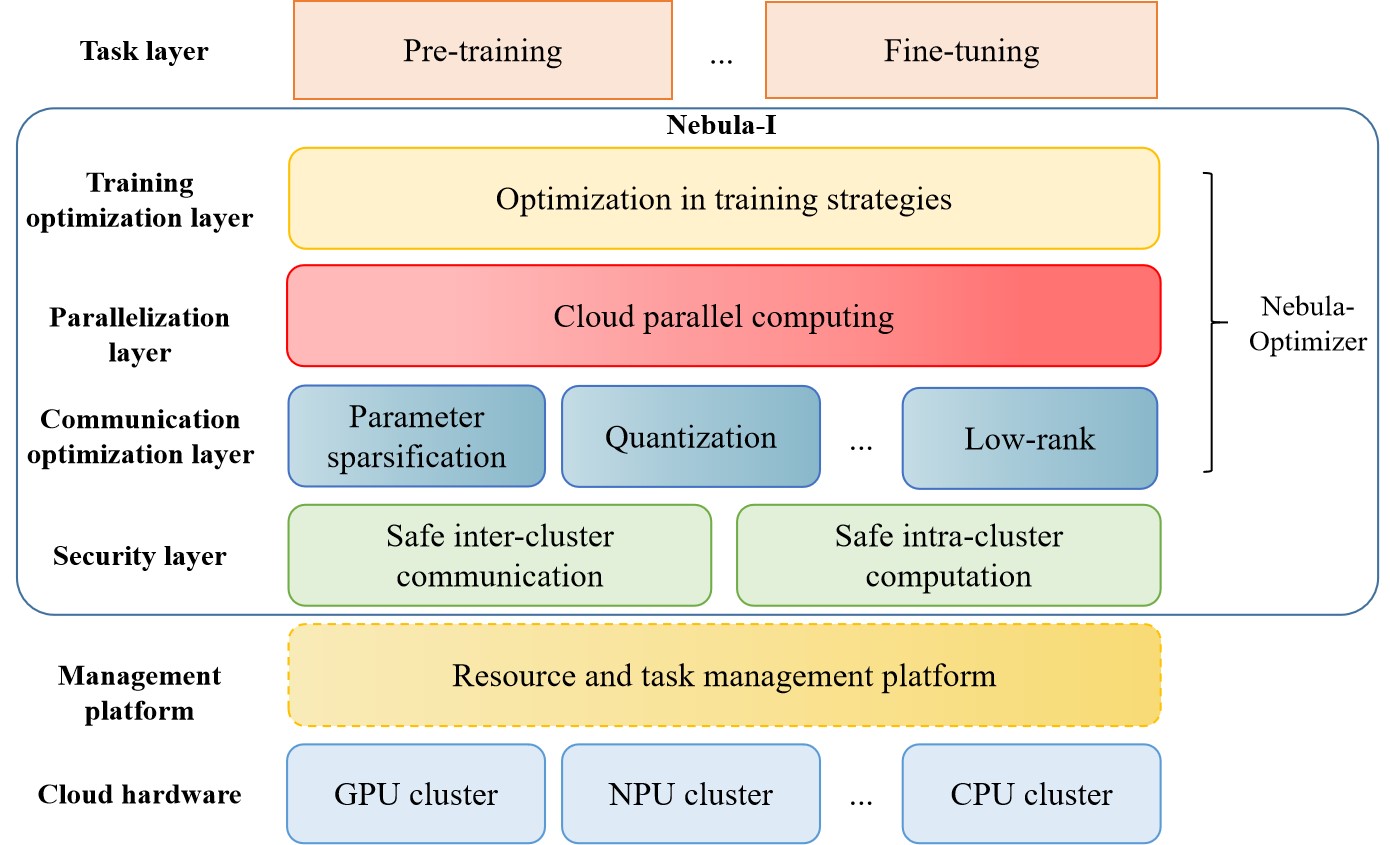
“鹏城-百度·星云(Nebula-I)”框架
据介绍,为验证其效用,研发团队采用“百度飞桨”实现“星云”框架,将其部署在公共互联网连接的,由“鹏城云脑I”(GPU)、“鹏城云脑II”(NPU)和“百度百舸”(GPU)三个算力集群组成的低带宽异构云际环境中,执行以ELECTRA算法为基础、复用已有模型“ERNIE-M”的多语言模型预训练任务以及以ABNet算法为基础、复用“ERNIE-M”和“BERT”模型的西班牙-英语翻译模型微调任务。验证结果显示,“星云”框架针对模型预训练任务能够有效保持模型训练的持续收敛,而且模型精度基本无损;在微调任务上获得的模型精度较单集群训练的结果损失较小,较transformer base模型则有较大提升。
目前,智算网络、云际协同训练等方向的研究还处于起步阶段,存在集群通信、异构软硬件适配、自适应并行等方面的许多技术难题。研发团队希望“星云”框架可为此领域科研工作者提供借鉴,为促进智算网络的建设与发展做出有益贡献。
